
Tulisan
ini dibuat untuk membantu siapapun yang sedang menghadapi skripsi,
terutama apabila skripsinya menggunakan data panel. Pengalaman pribadi
penulis yang kesulitan untuk setting data menjadi data panel pada beberapa software statistik menjadi latar belakang penulisan posting kali ini. Sebelumnya akan dikupas terlebih dahulu filosofi data panel itu sendiri.
Data panel merupakan data yang terbentuk
dari gabungan data time series dan
data cross section. Pada data cross section, nilai-nilai dari variabel
dikumpulkan untuk beberapa sampel unit pada satu titik waktu tertentu.
Kaitannya dengan data panel, data cross
section tersebut diteliti selama kurun waktu tertentu. Secara singkat,
dapat dikatakan data panel diperoleh dengan menggabungkan data cross section dan time series. Jika kita memiliki T
periode waktu (t = 1,2,...,T) dan n jumlah individu (i = 1,2,...,n) maka dengan
data panel kita akan memiliki total unit observasi sebanyak nT. Jika jumlah
unit waktu sama untuk setiap individu maka data disebut balanced panel, jika sebaliknya, yakni jumlah unit waktu berbeda
untuk setiap individu maka disebut unbalanced
panel.
Analisis regresi data panel mempunyai beberapa
keuntungan. Menurut Baltagi (2005), beberapa keuntungan tersebut adalah:
- Dengan menggabungkan data time series dan cross section, data panel menyediakan data yang lebih banyak dan dengan menggabungkan data time series dan cross section, panel menyediakan data yang lebih banyak dan informasi yang lebih lengkap serta bervariasi. Dengan demikian akan dihasilkan degress of freedom (derajat bebas) yang lebih besar dan mampu meningkatkan presisi dari estimasi yang dilakukan.
- Data panel mampu mengakomodasi tingkat heterogenitas individu-individu yang tidak diobservasi namun dapat mempengaruhi hasil dari permodelan (individual heterogenity). Hal ini tidak dapat dilakukan oleh studi time series maupun cross section sehingga dapat menyebabkan hasil yang diperoleh melalui kedua study ini akan menjadi bias.
- Data panel dapat digunakan untuk mempelajari kedinamisan data. Artinya dapat digunakan untuk memperoleh informasi bagaimana kondisi individu-individu pada waktu tertentu dibandingkan pada kondisinya pada waktu yang lainnya.
- Data panel dapat mengidentifikasikan dan mengukur efek yang tidak dapat ditangkap oleh data cross section murni maupun data time series murni.
- Data panel memungkinkan untuk membangun dan menguji model yang bersifat lebih rumit dibandingkan data cross section murni maupun data time series murni.
- Data panel dapat meminimalkan bias yang dihasilkan oleh agregasi individu karena unit observasi terlalu banyak.
Di dalam model regresi klasik, gangguan (error)
selalu dinyatakan homoskedastis dan serial
uncorrelate. Implikasinya, penggunaan OLS akan menghasilkan penduga yang
bersifat Best Linier Unbiased Estimator
(BLUE). Asumsi tersebut tidak dapat diterapkan untuk model data panel
karena disusun dari beberapa individu untuk beberapa periode yang membawa
masalah baru dalam sistem gangguan. Hal ini dikarenakan bertambahnya gangguan (disturbances) yang kini menjadi 3 macam,
yaitu: gangguan antar waktu (time series
related disturbances), gangguan antar individu (cross section disturbance) dan gangguan keduanya (Pindyck &
Rubinfeld, 1998).
Untuk
melakukan analisis regresi data panel, kebanyakan peneliti menggunakan
program E-Views atau STATA. Kedua program ini cukup populer mengingat
banyaknya tes yang bisa diuji, user friendly, dan referensi
statistik terhadap uji statistiknya mudah ditemukan dan bisa
dipertanggung jawabkan. Kelebihan program E-Views dibanding STATA adalah
program E-Views lebih user friendly. Apabila peneliti memutuskan untuk menggunakan program STATA, maka peneliti harus mengetahui syntaks untuk
uji-uji yang akan digunakan. Sementara itu kelebihan program STATA yang
tidak dimiliki oleh E-Views adalah kemudahan yang ditawarkan program
ini dalam menganalisis panel dinamis. Apa itu panel dinamis? Panel
dinamis adalah model panel yang memasukkan variabel lag dependen sebagai salah satu variabel independennya. Keberadaan variabel lag ini juga disinyalir bisa mengatasi permasalahan autokorelasi. Oleh karena itu salah satu keuntungan ini bisa kita peroleh apabila penelitian kita menggunakan data panel
Berikut disajikan secara singkat tutorial mengenai cara meng-input data panel pada kedua program tersebut.
1. Bentuk data panel di Microsoft Excel menjadi berstuktur seperti di bawah:
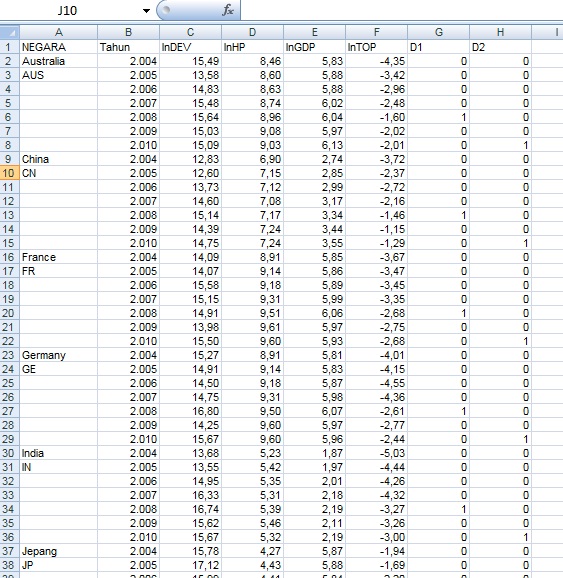
2. Kemudian buka program E-Views
 |
| Buka program E-Views |
3. Kemudian klik file, new, workfile. Kemudian isi start date dan end date (series tahun penelitian). Klik OK.

4. Klik Objek-New Objek

5. Klik Pool, kemudian isikan inisial data cross section yang sesuai dengan data di M.S

6. Klik proc, kemudian impor panel data, select data M.S yang telah disiapkan sebelumnya

7. Setelah itu, masukkan variabel dependen dan variabel independen ke dalam box ordinary dan pool. Klik OK

8. Setelah itu akan mucul dialog seperti di bawah. Penting untuk
dilakukan pengecekan apakah angka pada masing-masing variabel dan unit
penelitian sudah benar. Kadang sering ditemukan angka unit observasi
yang hilang (missing).


9. Setelah itu, baru dilakukan uji-uji regresi panel selanjutnya, seperti uji pemodelan terbaik (common, fixed, random), uji varians-covarians, dll.
Materi Pengujian Sig. Fexed Effect Model dapat diklik disitus berikut ini:
Materi Pengujian Sig. Fexed Effect Model dapat diklik disitus berikut ini:
Semoga cukup membantu ^_^
Tidak ada komentar:
Posting Komentar